



This article is one of the winning entries of Lexathon organised by NLU, Odisha, a technology law conclave on AI, data protection, and innovation which took place in April, 2026.
Introduction
Artificial intelligence (AI) is mutating into a genus of its own. Any legal framework falls short in stature and potential to tackle the rapid technological strides in this sphere. Interestingly, GenAI has emerged as an omnipresent specie within this genus. Unlike other orthodox and weak AI species, it is a stronger form of AI1 and can “create”, “reproduce” and “algorithmically profile” content.2 The bone of contention is the over-reliance on GenAI tools. In academia, law, and other professional fields, paraphrasing of ideas and thoughts with the aid of AI tools, has become commonplace. This not only leads to hallucinated citations, ratios, theories, but also compromises the integrity of the entire commune. Countries like Australia, India, UK, and the USA, with some of the most brilliant legal stalwarts, have become a battleground of hallucinated arguments and legal debates.3
Our research problematises the paraphrasing crisis which has normalised intellectual camouflage due to a dearth of qualitative AI-usage assessment mechanisms, but does not just restrict itself to problematisation. The aim is to dedicate a “Material Re-Expression Test” which will not just highlight the percentage of AI used in any write-up but will qualitatively structuralise and categorise the befitting usage of AI in refurbishment of the content. Further, the conscious conceptualisation of “Material Re-Expression Test” can awaken the legal community in particular and academia at large, to comprehensively analyse and extract out the substantial similarities in an original content and a paraphrased content. Much like the tests such as “Idea-Expression Dichotomy”,4 “Skill, Labour and judgment”,5 the legality of paraphrased content, and the due recognition to the work of the original author, cannot be sacrificed at the altar of intellectual misappropriation of thoughts and ideas.
“Sublato fundamento cadit opus” drawback of AI-generated content and the ethical dilemma
The maxim implies that “If the initial action is not in conformity with law, all subsequent and consequential proceedings fall through for the reason that illegality strikes at the root of the entire event.”6 In simple terms a statue cannot stand erect without its plinth. Analogically, paraphrasing strikes at the plinth of any research and parallelly hampers the legal interests of the original authors who deserve necessary acknowledgment in the form of citations, for their work.
Generative AI tools with their sophisticated Large Language Models (LLMs) are well trained and fed with “ground truths” so as to generate predictable responses that are closely aligned to the real-world scenarios.7 But the feeding of ground truths equally raises doubts vis-à-vis the neutrality of AI model. Two ethical questions emerge simultaneously due to uncontrolled usage and training of Generative AI:
(a) Bias in data and algorithmic patterns, and
(b) Collective normalisation of usurping someone’s creative work by not giving due recognition to the author and merely paraphrasing the same.8
The chilling example of such cheating writing can be utilisation of a fully AI generated work and submission of it as if the same has been executed end-to-end by oneself.9 This is the worst ethical outcome for an original author, because her work gets misappropriated without following the academic protocol of citation of that work.
AI randomises and borrows works directly from the internet without consent of the original author. But it does not stop at that; to beat plagiarism, the rewriting and paraphrasing of the text are the most commonly-employed strategy. Unlike traditional copying standards as part of plagiarism, this AI-generated content is extremely evolved, difficult to trace10 and has the potential to evade the traditional detection standards.11
Parallelly, when this usurpment of thought is backed with systemic biases and algorithmic prejudice,12 the principles of “fairness” and “due process” take a back seat. Thereby, they necessitate explainable AI models alongside an algorithmic impact assessment safeguard. “Critical Race Theory”13 by Crenshaw succinctly highlights this issue of bias in algorithmic training. The theory argues about the normalisation and organic structurisation of laws, literature, perceptions in such a way that racism gets embedded in the very roots of the system without any active or open revelation as to the same.
Such biases with respect to race, gender, etc. can unintentionally propagate structural inequalities which may be blindly utilised by an ignorant user of Generative AI. This biased and algorithmically processed outcome, coupled with paraphrased and rewritten intention of the original author, can be a highly misleading combination and can unfortunately promote misinterpretation and misrepresentation of thoughts and ideas.
To make a model explainable, there is a need for models such as Human-in-the-Loop AI (HITL)14, which not only muster human participation at the stage of data annotation but also require a multi-layer human participation through a continuous ongoing feedback mechanism. Therein, humans who verify the “ground truths” should be independent third-party evaluators15, much like independent auditors, so that the model’s outputs remain consistent with human values. To ensure more transparency, the evaluators can publish an Algorithmic Impact Assessment Report (AIAR) which will highlight the expectations from a trained AI model and its performance, flagging the potential biases, and propose a plan of action as to the elimination of certain “ground truths”.
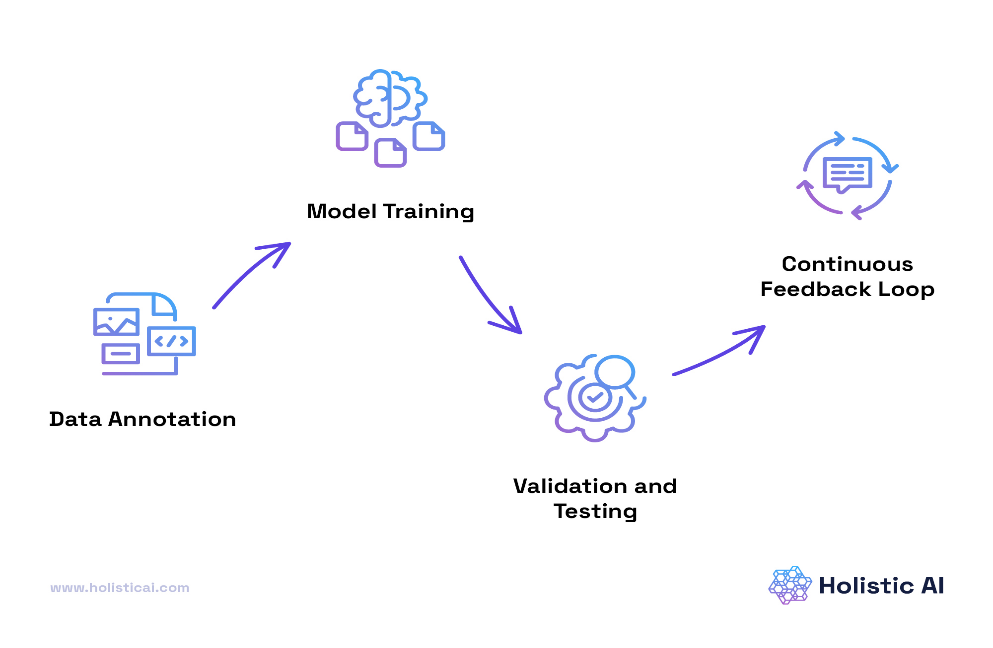
Figure 1 (Source: Holistic AI)
The abovementioned flowchart depicts the stages of active intervention on the part of human to keep a GenAI model in check. This is necessary from the standpoint of keeping biased, unverified, and misinformed thoughts out of academic discourse.
The curious case of Turnitin: The limitations of AI-detection software
The use of GenAI raises concerns about the veracity of data put in academic writing, in response to which some companies created “AI detection” software. This software is intended to detect AI-generated content. Unfortunately, AI detection software is far from foolproof—in fact, there are frequent errors16 and these can lead to instructors falsely accusing students of wrongdoing. In fact, there are instances of even the US Constitution and The Bible being flagged as AI-generated.17 This indicates how peripherally the AI-detection tools have been working, ultimately leading to complete shutdown for some like ChatGPT’s own AI detection tool.18
In academia, Turnitin is one popular tool to identify the instances of academic misconduct, it shows similarity and AI-content rates in its reports. Indeed, it is great for determining similarity from an existing database, but on the platform a low AI-content rate could constitute a false positive. Plagiarism detection software is unable to accurately identify information produced by artificial intelligence. As a result, though Turnitin provides assistance in identifying academic misconduct, the assignment’s originality, citations, linguistic mistakes, and consistency still need to be examined19 independently.
Now, Turnitin does not provide information on how it assesses whether a piece of writing is AI-generated or not. The most they have revealed is that their program looks for patterns common in AI writing, but they have not explained or defined such patterns.20 Which is precisely why, there is a need for a set of parameters, as we shall see later in this piece, to assess the originality of an academic work created by using GenAI.
Moreso, while other third-party software claims higher accuracy than Turnitin, there are legitimate privacy issues about collecting student data and feeding it into a detector run by a separate corporation with unknown privacy and data usage practices. Fundamentally, AI detection is currently a challenging issue for technology to accomplish, and it will only get more difficult as AI tools grow more prevalent and advanced.21
That said, it is true that detection software cannot always keep pace with the capacity of AI technologies to avoid detection. Relying on that program only addresses the symptoms of a much larger, multidimensional problem22 of plagiarising and posing content as one’s own. Therefore, some human intervention is crucial at these important stages.
The conceptualisation of the material re-expression test
With AI now segueing into each aspect of our lives, it becomes crucial to not only just problematise but also find alternatives to combat its substantial presence. This is peculiarly a case for domains involving “creativity” and “novelty”, terms that were traditionally believed to be illusory except if humans are not involved.23 Creative destruction24 is the coined term for this, and it explains the myriad ways to challenge every academic publication that has not been subjected to the use of AI-plagiarism, much less plagiarism in general.
1. The octad of parameters
Our shield to this inevitable brain-drain due to over-reliance on algorithmic technologies, is the Material Re-expression Test. It comprises of an eight-parameter octad: Purpose, structure, substance, effect, sentence complexity, jargon density, concept jumps and prior knowledge. Each of these presents a demand of human-engagement with the subject-matter.
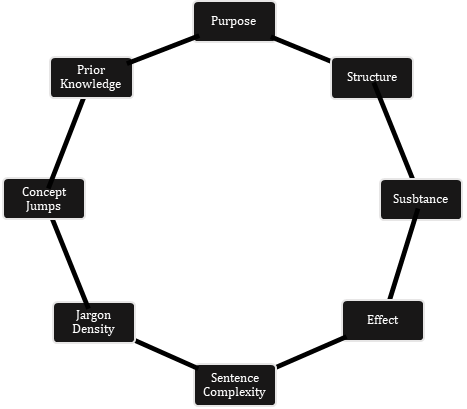
Figure 2: Octad of Material Re-expression Test
(a) Purpose: This is the objective criteria, and it tells us how coherent is the piece of work to the purpose of writing and overarching goals of the research, while highlighting contributions to the existing pool of knowledge.25 In the context of AI-generated works, instead of copying from a single source, AI uses the algorithmic patterns it has learned to generate new content.26 This often leads to content that is not originally created, but chunks of already existing content blended and presented as new.
(b) Structure: Similarities in the structure of the piece to the available data is intricately linked to the use of Generative AI. This is because, GenAI offers real-time grammatical and spelling corrections, it enhances the writing process and makes the content look flawless. Furthermore, AI algorithms can organise ideas, identify pertinent topics, and change the overall structure and coherence,27 based upon the existing data fed to it.
(c) Substance: The most important parameter is substance, since AI may generate incorrect data due to poor resources or biases28, and that is the primary reason for hallucinated content and citations. It ranges from false and unauthoritative information, incorrectly attributed information to the inability of the AI models to correct their own mistakes.29 Text generated by AI techniques is not static. It can be altered, revised, reworked, or remixed. This can lead to a hybrid product, written by both humans and AI and from then on, it is futile to try to distinguish between human and artificial intelligence.30 And as AI technologies improve, it becomes more difficult to distinguish between human and AI-generated text.31
(d) Effect: This is to assess the overall effect on the academic text. Since GenAI tools are educated on sets of data obtained from various sources, some AI picture and text generation systems were trained using scraped web page content without the owners’ agreement or knowledge.32 This manifests itself as a shared burden on copyright holders as well as intermediaries like online journals, web pages, and the like.
(e) Sentence complexity: This forms an easy manual identifier of text generated using AI. When GenAI systems try catching attention by shifting sentence structures, they frequently place emphasis where it does not belong, include unnecessary transition words, or push formulaic ends like “in summary”, which usually is not seen in an entirely human-generated output.33 As a result, this GenAI content lacks sentence diversity and natural variations because of its training based on large generalised datasets.34
(f) Jargon density: There is both stylistic undertones and potential tells of GenAI content. Largely a result of its training datasets, it leaves a linguistic footprint35 due to lack of human-creativity, intent, and independent thought process. This is where the new humanisation aspect of AI-models is also checked, where they instil similarity with human writing. There is little independent thought, and therefore, lesser ability to challenge notions. Instead, the AI models are trained for agreeableness and validation.
(g) Concept jumps: While GenAI models thrive at addressing typical problems, they struggle with activities that require in-depth reasoning and logic, particularly in unexpected or unstructured situations.36 This is often why such content takes leaps in reasoning, despite instructions to explain complex matter simply.
(h) Prior knowledge: Human-generated academic writing is typically influenced by their pre-conceived notions, prior knowledge, and awareness about the particular subject area. Although the bias angle sits well with AI-models as well, the major factor is that these models are inaccessible without prior knowledge on the subject area, and that precisely, is what is already existing over the web, instead of being interpreted in a particular way as a human.
2. Incorporating the factors to combat AI-driven refurbishment
It is now essential to look into how the MReT will work in practice. Take an academic assignment for instance, where the evaluator is tasked with the job of allocating marks for components like scope, methodology, clarity of thought, originality, etc. The 8 set of parameters listed above form guidelines for a manual, as well as a dedicated application-based assessment. Each step makes an operative approach to detection of AI-generated content more nuanced and holistic.
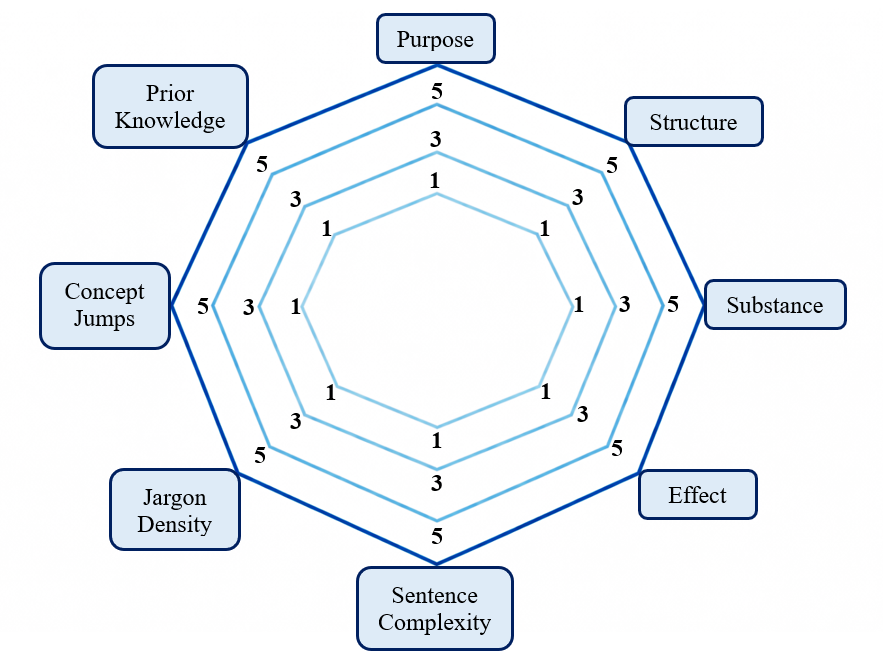
Figure 3: Scaling the MReT Octad
Starting with the core text quality elements, purpose is either focused, or frequently drifting, or completely departing. Then, structure denotes either coherence in articulation, or fragmented expression of ideas or logical sequences. Substance, being the most crucial, denotes conceptual depth and novelty and non-repetition or surface level reasoning. Effect is essentially the entire domain of copyright ownership being either affected or unaffected.
Then comes the cognitive load criteria of sentence complexity — visible in ideas either being compressed or reimagined altogether. Jargon density — is either maintaining academic precision or using explanatory terms to suffice for the argument put forth. Concept jumps — is transition into continuous parts smooth or sudden. Prior knowledge — is checking if the text is a reflection of the person’s prior personal experience or a mere reproduction of references without personal intent.
Evaluation of Generative AI content, based upon the above parameters, requires the same level of human intervention (by the course instructor/evaluator) as in grading any academic assignment. It becomes crucial since our assessment patterns have to adapt to the rapidly advancing developments and unprecedented level of precision that these systems now offer.37 The MReT, while still in its developmental stages and is a draft in refinement, is a useful guide to assess the originality in academic research and ensures that heavy reliance on Generative AI technologies does not compromise with the standards required in academic excellence.
The legal litmus of generative AI-driven refurbishment of content
Machine learning and the resultant outcomes are at loggerheads with different authors and journals. Reason being infringement of their copyright vis-à-vis their original, legally protected work. Tons of data are stored and processed in these AI models to effectively train them.38 But what about the unauthorised access being provided to that data by various AI tools along with utmost indifference being reflected towards the original copyrighted work.39
One of the classic examples of this entire crisis is the “French Competition Watchdog”40 case wherein Google Inc. faced a lawsuit of 250 million euros. It was claimed that they were training Gemini from copyrighted content of different publishers and agencies without their proper authorisation. Hence, the lawsuit and resultant penalty by the competition market regulator.
Further, if we interpret Article 13 of the TRIPS Agreement (which acts as a grundnorm in terms of framing of “fair dealing” and “fair use” provisions) states, “Members shall confine limitations or exceptions to exclusive rights to certain special cases which do not conflict with a normal exploitation of the work and do not unreasonably prejudice the legitimate interests of the right holder.”41
Now, the dissection of this provision and subsequent application of the same vis-à-vis the usage of GenAI, taking into consideration the Indian realities, gives a clear picture as to whether AI-generated content falls within the ambit contoured by the TRIPS Agreement. Firstly, large scale ingestion and processing of numerous sources for training purposes does not qualify as “certain special case”. Secondly, this trained AI is capable of generating independent and competitive works based on the aid provided by thousands of such copyrighted works, and therefore, “conflicts with the normal exploitation of work” undermining the very concept of licensing and digital access. Thirdly, it definitely dilutes the work of the author by endangering its exclusivity, affecting the author both economically42 and morally43.
Recently, Department for Promotion of Industry and Internal Trade (DPIIT) has come up with a “Working Paper” dated 8 December 202544 in which it advocates for a hybrid model of statutory licensing. This model aims to incentivise human creativity on one hand and adherence towards fair dealing exceptions by promising broader access, on the other. It proposes that AI developers can avail the content for training as a “matter of right” but have to ensure fair compensation (statutory remuneration right) to copyright holders. This remuneration would be collected by a centralised entity designated by the Central Government. Moreover, the rate setting is to be done in a very transparent manner with absolute mitigation of risk of AI bias.45 If we refer to the Annexure D46 of this working paper, Ministry of Electronics and Information Technology (MeitY) has also been a key proponent of this hybrid approach. According to MeitY, Copy Royalties Collective for Training (CRCAT) will be responsible for prescribing a minimum revenue threshold as a bar, above which the royalty sharing is supposed to operate.
The report, further citing Lemley and Weiser, made a key observation that a “zero-price licence i.e. an outright blanket exception under law in favour of use of copyrighted materials for AI training without any payment to copyright holders, can polarise the income in the value chain for AI, reducing the incentive to human creativity.”47 This marked a departure from the “closed door” approach of protection of rights and places us in the one of the elite AI-embracing frontrunners.
In the initial stages of development of GenAI, there are recorded instances of courts experimenting with ChatGPT and similar AI tools. In a recent case of Jaswinder Singh v. State of Punjab48, the court itself disclosed that in order to determine the relevant jurisprudence, it went ahead with a generative pre-trained transformer (GPT) generated response. But this came with a caveat that such an AI-generated observation will neither be counted as a ratio on merits nor the trial court is supposed to advert to these comments. This was only experimented with an intention to present a broad outlook as to the pressing issue in that case. This sensitisation towards GenAI and a progression towards responsible AI usage is the need of the hour. But the same can be achieved by following an approach that recognises an author’s creativity and free flow of thoughts and expressions on the internet at the same time.
For the legal practitioners, major challenge lies in the reproduction of hallucinated citations and case briefs with artificially created/assumed facts and circumstances. In a notable case of Mata v. Avianca Inc.49 lawyers were sanctioned a huge penalty for submitting multiple fabricated citations and judicial opinions. These fictitious submissions not only hamper the legal interests of a client but also lower the authority of courts in the eyes of general public. This also raises a big question mark on the sanctity of legal practitioners as officers of the court.
Conclusion
The overarching presence of GenAI in academia, the legal profession and other associated fields has been subjected to huge criticism due to its black-box functioning vis-à-vis its handling of data from millions of resources. Furthermore, it has also largely failed to make itself explainable and devoid of biases. Though it has emerged as a beacon of hope in the form of an open access source, it is conceptually and procedurally opaque. For the due recognition to authors of original work, a qualitative, quantifiable, and answerable GenAI scale is the need of the hour. Through Material Re-Expression Test (MReT), the research aims to offer a humanised and comprehensive framework to assess the level and kind of AI used in drafting. The Octad of parameters including purpose, structure, substance, effect, sentence complexity, jargon density, concept jumps and prior knowledge, can lead to genesis of responsible and informed AI detection. Turnitin, a very advanced and meticulous software also faces certain challenges in processing and evaluating AI usage with complete accuracy and context. Simultaneously, the copyright tensions that accompany this unauthorised ingestion of millions of resources without proper acknowledgement pose significant obstacles to the functioning of TRIPS Agreement and Copyright Act, respectively. Hence, a human in the loop model, algorithmic impact assessment report by independent third-party evaluators and a hybrid model of statutory licensing and remuneration can come to rescue. As and when technology develops, there needs to be neutral and informed processes in place to tackle its uncontrolled expanse.
*Final Year Student, Maharashtra National Law University, Nagpur.
**Final Year Student, Maharashtra National Law University, Nagpur.
1. What is strong AI?, IBM (17-11-2025), available at <https://www.ibm.com/think/topics/strong-ai> last accessed 29-1-2026.
2. Joe Devanny, Huw Dylan, and Elena Grossfeld, “Generative AI and Intelligence Assessment” (2023) 168(7) The RUSI Journal, available at <https://doi.org/10.1080/03071847.2023.2286775> last accessed 2-2-2026.
3. Damien Charlotin, “AI Hallucination Cases”, available at <https://www.damiencharlotin.com/hallucinations/?q=&sort_by=date&period_idx=0> last accessed 15-1-2026.
4. R.G. Anand v. Delux Films, (1978) 4 SCC 118.
5. Walter v. Lane, 1900 AC 539; Centre for Intellectual Property and Information Law, “Walter v Lane, [1900] A.C. 539, University of Cambridge, available at <https://www.cipil.law.cam.ac.uk/virtual-museum/walter-v-lane-1900-ac-539> last accessed 10-2-2026.
6. LIC v. Shiv Kumar Sharma, 2007 SCC OnLine All 1380.
7. Tom Krantz and Alexandra Jonker, “What is Ground Truth?”, IBM, available at <https://www.ibm.com/think/topics/ground-truth> last accessed 28-1-2026.
8. Louie Giray, Jomarie Jacob et al, “Cheating Writing with Generative AI: Exploring Student Motivations Using the Theory of Planned Behavior” (2026) 24 Journal of Academic Ethics, available at <https://doi.org/10.1007/s10805-025-09695-z> last accessed 28-1-2026.
9. Fiona Draxler, Anna Werner et al, “The AI Ghostwriter Effect: When Users do not Perceive Ownership of AI-Generated Text but Self-Declare as Authors” (2024) 31(2) ACM Transactions on Computer-Human Interaction, available at <https://doi.org/10.1145/3637875> last accessed 28-1-2026.
11. Mohammad Khalil and Erkan Er, “Will ChatGPT Get You Caught? Rethinking of Plagiarism Detection”, International Conference on Human-Computer Interaction, Sweden, 2025 (Springer Nature 2023), available at <https://doi.org/10.1007/978-3-031-34411-4_32> last accessed 28-1-2026.
12. Yuliya Kharitonova, V.S. Savina, and F. Pagnini, “Artificial Intelligence’s Algorithmic Bias: Ethical and Legal Issues” (2021), available at <https://doi.org/10.17072/1995-4190-2021-53-488-515> last accessed 30-1-2026.
13. Janel George, “A Lesson on Critical Race Theory”, American Bar Association (11-1-2021), available at <https://www.americanbar.org/groups/crsj/resources/human-rights/archive/lesson-critical-race-theory/> last accessed 3-2-2026.
14. Holistic AI Team, “Human in the Loop AI: Keeping AI Aligned with Human Values”, Holistic AI (4-10-2024), available at <https://www.holisticai.com/blog/human-in-the-loop-ai> last accessed 4-2-2026.
15. US Department of Commerce, Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile (Report, NIST AI 600-1, 2024) Para 3 <https://doi.org/10.6028/NIST.AI.600-1> last accessed 4-2-2026.
16. “AI Detectors Don’t Work. Here’s What to Do Instead”, MIT Management, available at <https://mitsloanedtech.mit.edu/ai/teach/ai-detectors-dont-work/> last accessed 4-2-2026.
17. Benj Edwards, “Why AI Writing Detectors don’t Work”, Ars Technica (14-7-2023), available at <https://arstechnica.com/information-technology/2023/07/why-ai-detectors-think-the-us-constitution-was-written-by-ai/> last accessed 4-2-2026.
18. Jason Nelson, “OpenAI Quietly Shuts Down Its AI Detection Tool”, Decrypt (25-7-2023), available at <https://decrypt.co/149826/openai-quietly-shutters-its-ai-detection-tool> last accessed 4-2-2026.
19. Akash Gupta, Harsh Mahaseth, and Arushi Bajpai, “AI Detection in Academia: How Indian Universities Can Safeguard Academic Integrity” (2025) 107(1), 26 Engineering Proceedings, available at <https://doi.org/10.3390/engproc2025107026> last accessed 3-2-2026.
20. Michael Coley, “Guidance on AI Detection and Why We’re Disabling Turnitin’s AI Detector”, Vanderbilt University (16-8-2023) available at <https://www.vanderbilt.edu/brightspace/2023/08/16/guidance-on-ai-detection-and-why-were-disabling-turnitins-ai-detector/> last accessed 3-2-2026.
21. Michael Coley, “Guidance on AI Detection and Why We’re Disabling Turnitin’s AI Detector”, Vanderbilt University (16-8-2023) <https://www.vanderbilt.edu/brightspace/2023/08/16/guidance-on-ai-detection-and-why-were-disabling-turnitins-ai-detector/> last accessed 3-2-2026.
22. “Why You Should Use Caution with AI Detectors”, The University of Kansas, available at <https://cte.ku.edu/careful-use-ai-detectors> last accessed 3-2-2026.
23. Madeleine de Cock Buning, “Autonomous Intelligent Systems as Creative Agents under the EU Framework for Intellectual Property” (2016) 7(2) European Journal of Risk Regulation 311, available at <https://www.jstor.org/stable/24769811> last accessed 3-2-2026.
24. Stuart Macdonald, “Artificial Intelligence and Academic Publishing” (2024) 40(2) Prometheus <https://www.jstor.org/stable/10.2307/48820018> last accessed 3-2-2026.
25. Prince Edike, “A Comprehensive Framework for Evaluating Scholarly Research Papers”, Medium (11-12-2023) available at <https://medium.com/@princeblockchain/a-comprehensive-framework-for-evaluating-scholarly-research-papers-d530515fddcc> last accessed 3-2-2026.
26. Akash Gupta, Harsh Mahaseth, and Arushi Bajpai, “AI Detection in Academia: How Indian Universities Can Safeguard Academic Integrity” (2025) 107(1), 26 Engineering Proceedings <https://doi.org/10.3390/engproc2025107026> last accessed 3-2-2026.
27. Zoleikha Shahbazi, Ebrahim Mohammadkarimi et al., “The Role of Artificial Intelligence in Transforming the Writing Process: Benefits, Limitations, and Future Opportunities” (2025) 5(2) Journal of Digital Educational Technology 2.
28. Ljubinko Stojanovic, Vesna Radojcic et al., “The Influence of Artificial Intelligence on Creative Writing: Exploring the Synergy between AI and Creative” (2023) 12(12) International Journal of Engineering Inventions 72.
29. Ting Tian, Ching Sing Chai et al., “University Students’ Perceptions of Learning with Generative Artificial Intelligence” (2025) 28(3) Educational Technology & Society 158.
30. Sarah Elaine Eaton, “Postplagiarism: Transdisciplinary Ethics and Integrity in the Age of Artificial Intelligence and Neurotechnology” (2023) 19, 23 International Journal for Educational Integrity, available at <https://doi.org/10.1007/s40979-023-00144-1> last accessed 5-2-2026.
31. Ahmed M. Elkhatat, Khaled Elsaid, and Saeed Almeer, “Evaluating the Efficacy of AI Content Detection Tools in Differentiating between Human and AI-generated Text” (2023) 19 International Journal for Educational Integrity, available at <https://doi.org/10.1007/s40979-023-00140-5> last accessed 5-2-2026.
32. AI Tools and Resources: Copyright and Generative AI, University of South Florida (3-2-2026) available at <https://guides.lib.usf.edu/AI/copyright> last accessed 6-2-2026.
33. Danielle Cosimo and Ivy B. Grey, “Weaknesses of AI-Generated Writing—and Why You Must Edit”, WordRake available at <https://www.wordrake.com/resources/weaknesses-of-ai-generated-writing> last accessed 6-2-2026.
34. Elena Shalevska, “Sentence Structure in Human and AI-Generated Texts: A Comparative Study” (2025) 10(19) Palimpsest 16.
35. Anup Chaudhari, “Most Common Words and Phrases in AI-Generated Content”, HumanizeAI (15-6-2025), available at <https://www.humanizeai.io/blog/article/most-common-words-and-phrases-in-ai-generated-content> last accessed 6-2-2026.
36. Kolawole Samuel Adebayo, “AI Models Still Struggle With Reasoning — And Here’s Why”, Forbes (22-5-2025), available at <https://www.forbes.com/sites/kolawolesamueladebayo/2025/05/22/ai-models-still-struggle-with-reasoning—and-heres-why/> last accessed 6-2-2026.
37. Frederick Boafo, Patrick Amfo Anim and Emmanuel Arthur, “Effective Ways of Assessment in the AI Era”(2024) Proceedings of the Lancaster University Education Conference 2, available at <https://ojs.library.lancs.ac.uk/lue/article/download/12/8/26> last accessed 6-2-2026.
38. Liu Youhua and Wei Yuanshan, “Copyright Infringement Problem of Machine Learning and Its Solution” (2019) 22(2) Journal of East China University of Political Science and Law.
39. Weixi Song, “A Study of Copyright Issues in the Input Phase of Generative Artificial Intelligence Machine Learning” in Proceedings of the 1st International Conference on Innovative Education and Social Development (SCITEPRESS 2025).
40. Reuters, “French Competition Watchdog Hits Google with 250 Million Euro Fine” (20-3-2024), available at <https://www.reuters.com/technology/french-competition-watchdog-hits-google-with-250-mln-euro-fine-2024-03-20/> last accessed 8-2-2026.
41. Agreement on Trade-Related Aspects of Intellectual Property Rights, 1869 UNTS 299, 33 ILM 1197 (1994), Art. 13.
42. Copyright Act, 1957, S. 14.
43. Copyright Act, 1957, S. 57.
44. DPIIT, “One Nation One License One Payment: Balancing AI Innovation and Copyright”, Working Paper on Generative AI and Copyright, 60 (December 2025), available at <https://www.dpiit.gov.in/static/uploads/2025/12/ff266bbeed10c48e3479c941484f3525.pdf> last accessed 9-2-2026.
45. DPIIT, “One Nation One License One Payment: Balancing AI Innovation and Copyright”, Working Paper on Generative AI and Copyright, 60 (December 2025), available at <https://www.dpiit.gov.in/static/uploads/2025/12/ff266bbeed10c48e3479c941484f3525.pdf> last accessed 9-2-2026.
46. DPIIT, “One Nation One License One Payment: Balancing AI Innovation and Copyright”, Working Paper on Generative AI and Copyright, 60, 89 (December 2025), available at <https://www.dpiit.gov.in/static/uploads/2025/12/ff266bbeed10c48e3479c941484f3525.pdf> last accessed 9-2-2026.
47. DPIIT, “One Nation One License One Payment: Balancing AI Innovation and Copyright”, Working Paper on Generative AI and Copyright, 55, 60 (December 2025) <https://www.dpiit.gov.in/static/uploads/2025/12/ff266bbeed10c48e3479c941484f3525.pdf> last accessed 9-2-2026.
48. 2023 SCC OnLine P&H 2587; Talha Abdul Rahman, “ChatGPTfication of the Judicial Process”, 2023 SCC OnLine Blog OpEd 148.





